



UPDATE LOG
- complete the kernel Generate Training Samples NeRF
NOTEThis draft is base on the commit
d64e353db28109a81657879fc88025713d8fad53(Oct 8, 2025)Instant-NGP Official Repository:
Waiting for api.github.com...
1. Introduction and Motivation
In this article, we’re going to untangle the core training pipeline, in a first-principle manner, and finally rewrite a clean, tidy, modern, and easy-to-understand version, and achieve better performance.
2. Kernel: Generate Training Samples NeRF
Location:
instant-ngp/src/testbed_nerf.cu->generate_training_samples_nerf
Parameters List
| Name | Type |
|---|---|
n_rays | uint32_t |
aabb | BoundingBox (custom struct) |
max_samples | uint32_t |
n_rays_total | uint32_t |
rng | default_rng_t (PCG RNG wrapper) |
ray_counter | uint32_t* |
numsteps_counter | uint32_t* |
ray_indices_out | uint32_t* |
rays_out_unnormalized | Ray* (custom ray structure pointer) |
numsteps_out | uint32_t* |
coords_out | PitchedPtr |
n_training_images | uint32_t |
metadata | TrainingImageMetadata* (per-image camera + rays + focal info) |
training_xforms | TrainingXForm* (start/end view transform, rolling shutter) |
density_grid | const uint8_t* |
max_mip | uint32_t |
max_level_rand_training | bool |
max_level_ptr | float* |
snap_to_pixel_centers | bool |
train_envmap | bool |
cone_angle_constant | float |
distortion | Buffer2DView |
cdf_x_cond_y | const float* |
cdf_y | const float* |
cdf_img | const float* |
cdf_res | ivec2 (2D integer vector) |
extra_dims_gpu | const float* |
n_extra_dims | uint32_t |
Click here to show complete code
__global__ void generate_training_samples_nerf( const uint32_t n_rays, BoundingBox aabb, const uint32_t max_samples, const uint32_t n_rays_total, default_rng_t rng, uint32_t* __restrict__ ray_counter, uint32_t* __restrict__ numsteps_counter, uint32_t* __restrict__ ray_indices_out, Ray* __restrict__ rays_out_unnormalized, uint32_t* __restrict__ numsteps_out, PitchedPtr<NerfCoordinate> coords_out, const uint32_t n_training_images, const TrainingImageMetadata* __restrict__ metadata, const TrainingXForm* training_xforms, const uint8_t* __restrict__ density_grid, uint32_t max_mip, bool max_level_rand_training, float* __restrict__ max_level_ptr, bool snap_to_pixel_centers, bool train_envmap, float cone_angle_constant, Buffer2DView<const vec2> distortion, const float* __restrict__ cdf_x_cond_y, const float* __restrict__ cdf_y, const float* __restrict__ cdf_img, const ivec2 cdf_res, const float* __restrict__ extra_dims_gpu, uint32_t n_extra_dims){ const uint32_t i = threadIdx.x + blockIdx.x * blockDim.x; if (i >= n_rays) { return; }
uint32_t img = image_idx(i, n_rays, n_rays_total, n_training_images, cdf_img); ivec2 resolution = metadata[img].resolution;
rng.advance(i * N_MAX_RANDOM_SAMPLES_PER_RAY()); vec2 uv = nerf_random_image_pos_training(rng, resolution, snap_to_pixel_centers, cdf_x_cond_y, cdf_y, cdf_res, img);
// Negative values indicate masked-away regions size_t pix_idx = pixel_idx(uv, resolution, 0); if (read_rgba(uv, resolution, metadata[img].pixels, metadata[img].image_data_type).x < 0.0f) { return; }
float max_level = max_level_rand_training ? (random_val(rng) * 2.0f) : 1.0f; // Multiply by 2 to ensure 50% of training is at max level
float motionblur_time = random_val(rng);
const vec2 focal_length = metadata[img].focal_length; const vec2 principal_point = metadata[img].principal_point; const float* extra_dims = extra_dims_gpu + img * n_extra_dims; const Lens lens = metadata[img].lens;
const mat4x3 xform = get_xform_given_rolling_shutter(training_xforms[img], metadata[img].rolling_shutter, uv, motionblur_time);
Ray ray_unnormalized; const Ray* rays_in_unnormalized = metadata[img].rays; if (rays_in_unnormalized) { // Rays have been explicitly supplied. Read them. ray_unnormalized = rays_in_unnormalized[pix_idx];
/* DEBUG - compare the stored rays to the computed ones const mat4x3 xform = get_xform_given_rolling_shutter(training_xforms[img], metadata[img].rolling_shutter, uv, 0.f); Ray ray2; ray2.o = xform[3]; ray2.d = f_theta_distortion(uv, principal_point, lens); ray2.d = (xform.block<3, 3>(0, 0) * ray2.d).normalized(); if (i==1000) { printf("\n%d uv %0.3f,%0.3f pixel %0.2f,%0.2f transform from [%0.5f %0.5f %0.5f] to [%0.5f %0.5f %0.5f]\n" " origin [%0.5f %0.5f %0.5f] vs [%0.5f %0.5f %0.5f]\n" " direction [%0.5f %0.5f %0.5f] vs [%0.5f %0.5f %0.5f]\n" , img,uv.x, uv.y, uv.x*resolution.x, uv.y*resolution.y, training_xforms[img].start[3].x,training_xforms[img].start[3].y,training_xforms[img].start[3].z, training_xforms[img].end[3].x,training_xforms[img].end[3].y,training_xforms[img].end[3].z, ray_unnormalized.o.x,ray_unnormalized.o.y,ray_unnormalized.o.z, ray2.o.x,ray2.o.y,ray2.o.z, ray_unnormalized.d.x,ray_unnormalized.d.y,ray_unnormalized.d.z, ray2.d.x,ray2.d.y,ray2.d.z); } */ } else { ray_unnormalized = uv_to_ray(0, uv, resolution, focal_length, xform, principal_point, vec3(0.0f), 0.0f, 1.0f, 0.0f, {}, {}, lens, distortion); if (!ray_unnormalized.is_valid()) { ray_unnormalized = {xform[3], xform[2]}; } }
vec3 ray_d_normalized = normalize(ray_unnormalized.d);
vec2 tminmax = aabb.ray_intersect(ray_unnormalized.o, ray_d_normalized); float cone_angle = calc_cone_angle(dot(ray_d_normalized, xform[2]), focal_length, cone_angle_constant);
// The near distance prevents learning of camera-specific fudge right in front of the camera tminmax.x = fmaxf(tminmax.x, 0.0f);
float startt = advance_n_steps(tminmax.x, cone_angle, random_val(rng)); vec3 idir = vec3(1.0f) / ray_d_normalized;
// first pass to compute an accurate number of steps uint32_t j = 0; float t = startt; vec3 pos;
while (aabb.contains(pos = ray_unnormalized.o + t * ray_d_normalized) && j < NERF_STEPS()) { float dt = calc_dt(t, cone_angle); uint32_t mip = mip_from_dt(dt, pos, max_mip); if (density_grid_occupied_at(pos, density_grid, mip)) { ++j; t += dt; } else { t = advance_to_next_voxel(t, cone_angle, pos, ray_d_normalized, idir, mip); } } if (j == 0 && !train_envmap) { return; } uint32_t numsteps = j; uint32_t base = atomicAdd(numsteps_counter, numsteps); // first entry in the array is a counter if (base + numsteps > max_samples) { return; }
coords_out += base;
uint32_t ray_idx = atomicAdd(ray_counter, 1);
ray_indices_out[ray_idx] = i; rays_out_unnormalized[ray_idx] = ray_unnormalized; numsteps_out[ray_idx * 2 + 0] = numsteps; numsteps_out[ray_idx * 2 + 1] = base;
vec3 warped_dir = warp_direction(ray_d_normalized); t = startt; j = 0; while (aabb.contains(pos = ray_unnormalized.o + t * ray_d_normalized) && j < numsteps) { float dt = calc_dt(t, cone_angle); uint32_t mip = mip_from_dt(dt, pos, max_mip); if (density_grid_occupied_at(pos, density_grid, mip)) { coords_out(j)->set_with_optional_extra_dims(warp_position(pos, aabb), warped_dir, warp_dt(dt), extra_dims, coords_out.stride_in_bytes); ++j; t += dt; } else { t = advance_to_next_voxel(t, cone_angle, pos, ray_d_normalized, idir, mip); } }
if (max_level_rand_training) { max_level_ptr += base; for (j = 0; j < numsteps; ++j) { max_level_ptr[j] = max_level; } }}2.1 CUDA indexing formula
const uint32_t i = threadIdx.x + blockIdx.x * blockDim.x;if (i >= n_elements){ return;}2.1.1 Global Thread Index [1]
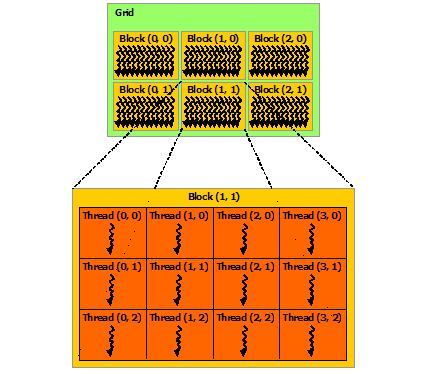
| Term | Meaning |
|---|---|
| index of thread inside its block | |
| index of block inside the grid | |
| number of threads per block |
2.2 Determine image index for a given ray
uint32_t img = image_idx(i, n_rays, n_rays_total, n_training_images, cdf_img);2.2.1 CUDA Function image_idx
inline NGP_HOST_DEVICE uint32_t image_idx(uint32_t base_idx, uint32_t n_rays, uint32_t n_rays_total, uint32_t n_training_images, const float* __restrict__ cdf = nullptr, float* __restrict__ pdf = nullptr) { if (cdf) { float sample = ld_random_val(base_idx/* + n_rays_total*/, 0xdeadbeef); // float sample = random_val(base_idx/* + n_rays_total*/); uint32_t img = binary_search(sample, cdf, n_training_images);
if (pdf) { float prev = img > 0 ? cdf[img-1] : 0.0f; *pdf = (cdf[img] - prev) * n_training_images; }
return img; }
// return ((base_idx/* + n_rays_total*/) * 56924617 + 96925573) % n_training_images;
// Neighboring threads in the warp process the same image. Increases locality. if (pdf) { *pdf = 1.0f; } return (((base_idx/* + n_rays_total*/) * n_training_images) / n_rays) % n_training_images;}| Parameter | Type | Note |
|---|---|---|
base_idx | uint32_t | Unique ray/thread index used for hashing image selection |
n_rays | uint32_t | Total rays scheduled in current iteration (controls uniform mapping) |
n_rays_total | uint32_t | (Unused in training — relevance removed) |
n_training_images | uint32_t | Number of images available for sampling (upper bound of output index) |
cdf | const float* | Optional CDF for importance sampling — always nullptr in NeRF training |
pdf | float* | Output for probability weight only used when cdf != nullptr (never touched in training) |
2.2.2 Base Version
__device__ uint32_t image_idx( const uint32_t base_idx, const uint32_t n_rays, const uint32_t n_training_images ) { return base_idx * n_training_images / n_rays % n_training_images;}Intuitive interpretation: Each image receives approximately rays. Rays are distributed proportionally among the images.
Where:
| Symbol | Corresponding variable |
|---|---|
base_idx | |
n_rays | |
n_training_images |
2.2.3 CDF and PDF
For more details about CDF and PDF, please refer to Appendix CDF: Cumulative Distribution Function.
TODO: explain the CDF & PDF branch
2.3 Get Image Resolution
ivec2 resolution = metadata[img].resolution;2.3.1 TrainingImageMetadata Struct
struct TrainingImageMetadata { // Camera intrinsics and additional data associated with a NeRF training image // the memory to back the pixels and rays is held by GPUMemory objects in the NerfDataset and copied here. const void* pixels = nullptr; EImageDataType image_data_type = EImageDataType::Half;
const float* depth = nullptr; const Ray* rays = nullptr;
Lens lens = {}; ivec2 resolution = ivec2(0); vec2 principal_point = vec2(0.5f); vec2 focal_length = vec2(1000.f); vec4 rolling_shutter = vec4(0.0f); vec3 light_dir = vec3(0.f); // TODO: replace this with more generic float[] of task-specific metadata.};| Field | Type | Meaning |
|---|---|---|
pixels | const void* | Pointer to pixel buffer in GPU memory |
image_data_type | EImageDataType | Pixel storage format (Byte/Half Float etc.) |
depth | const float* | Optional depth values per pixel (nullable) |
rays | const Ray* | Optional precomputed rays (nullable) |
lens | Lens | Lens configuration (distortion and optical parameters) |
resolution | ivec2 | Image width & height |
principal_point | vec2 | Camera optical center offset |
focal_length | vec2 | Focal length fx, fy |
rolling_shutter | vec4 | Rolling shutter timing & motion model |
light_dir | vec3 | View lighting direction (non-general metadata placeholder) |
2.3.2 How to compute resolution
NOTEIn order to avid being trapped in the endless details of image loading and preprocessing, we now assume the image resolution is precomputed and stored in the
TrainingImageMetadatastruct. We will cover the image loading and preprocessing in a future article.
Here, for NeRF Synthetic dataset, we can simply assume the resolution is a constant (800 x 800). (Obviously, it’s a safe assumption that all images in the dataset share the same resolution and never change during training.)
2.4 Advance RNG State
rng.advance(i * N_MAX_RANDOM_SAMPLES_PER_RAY());2.4.1 default_rng_t (tcnn::pcg32) Struct
default_rng_t (tcnn::pcg32) is a wrapper around the PCG Random Number Generator. For more details about PCG, please refer to Appendix PCG: Permuted Congruential Generator.
2.4.2 Why advance RNG state?
In tiny-cuda-nn / instant-ngp, each CUDA thread generates one ray:
const uint32_t i = threadIdx.x + blockIdx.x * blockDim.x; // unique per threadrng.advance(i * N_MAX_RANDOM_SAMPLES_PER_RAY());This line is not random — it is a design requirement.
PCG produces a sequence of numbers. A PCG generator is deterministic:
If all threads start with the same RNG state, then:
| Thread | RNG values |
|---|---|
| Thread 0 | 0.83, 0.21, 0.55, … |
| Thread 1 | 0.83, 0.21, 0.55, … |
| Thread 2 | 0.83, 0.21, 0.55, … |
- every pixel ray gets the same random samples
- training collapses (all rays identical → no learning)
2.4.3 How advance(k) jumps ahead in the PCG sequence
The function:
rng.advance(K);mathematically means:
It fast-forwards the PCG stream without generating intermediate numbers.
Each thread should get different random numbers, so they offset the RNG state using the thread ID:
That means:
Thread i | RNG will begin at position |
|---|---|
| 0 | base + 0stride |
| 1 | base + 1stride |
| 2 | base + 2stride |
| … | … |
Therefore:
- no collision
- parallel-safe randomness
- deterministic reproducibility
2.4.4 Why multiply by N_MAX_RANDOM_SAMPLES_PER_RAY()?
Because each ray will generate up to that many random numbers. So they space threads far enough apart so streams don’t overlap.
If worst case = 64 random samples per ray, then:
Ray index i | RNG range reserved |
|---|---|
| 0 | 0–63 |
| 1 | 64–127 |
| 2 | 128–191 |
Each ray lives in its own section of the RNG sequence.
2.5 Sample Image Position
vec2 uv = nerf_random_image_pos_training(rng, resolution, snap_to_pixel_centers, cdf_x_cond_y, cdf_y, cdf_res, img);2.5.1 CUDA Function nerf_random_image_pos_training
inline __device__ vec2 nerf_random_image_pos_training(default_rng_t& rng, const ivec2& resolution, bool snap_to_pixel_centers, const float* __restrict__ cdf_x_cond_y, const float* __restrict__ cdf_y, const ivec2& cdf_res, uint32_t img, float* __restrict__ pdf = nullptr) { vec2 uv = random_val_2d(rng);
if (cdf_x_cond_y) { uv = sample_cdf_2d(uv, img, cdf_res, cdf_x_cond_y, cdf_y, pdf); } else { // // Warp-coherent tile // uv.x = __shfl_sync(0xFFFFFFFF, uv.x, 0); // uv.y = __shfl_sync(0xFFFFFFFF, uv.y, 0);
// const ivec2 TILE_SIZE = {8, 4}; // uv = (uv * vec2(resolution - TILE_SIZE) + vec2(tcnn::lane_id() % TILE_SIZE.x, tcnn::lane_id() / threadIdx.x)) / vec2(resolution);
if (pdf) { *pdf = 1.0f; } }
if (snap_to_pixel_centers) { uv = (vec2(clamp(ivec2(uv * vec2(resolution)), 0, resolution - 1)) + 0.5f) / vec2(resolution); }
return uv;}| Parameter | Type | Note |
|---|---|---|
rng | default_rng_t& | Random number generator reference — mutated each call |
resolution | ivec2 | Image width/height used to scale UV coordinates |
snap_to_pixel_centers | bool | If true, UV snapped to pixel center rather than continuous sampling |
cdf_x_cond_y | const float* (optional) | X-conditioned CDF table for importance sampling — if non-null enables 2D CDF sampling |
cdf_y | const float* (optional) | Marginal distribution along Y axis for CDF sampling |
cdf_res | ivec2 | Resolution of CDF grid (width,height) corresponding to cdf_x_cond_y/cdf_y |
img | uint32_t | Image index — determines which image’s CDF to sample from |
pdf | float* (optional) | Output probability density — set only if CDF sampling used or PDF requested |
2.5.2 Base Version
__device__ tcnn::vec2 nerf_random_image_pos_training( tcnn::pcg32& rng, const tcnn::ivec2& resolution, const bool snap_to_pixel_centers ) { tcnn::vec2 uv = {rng.next_float(), rng.next_float()};
if (snap_to_pixel_centers) { uv = (tcnn::vec2(tcnn::clamp(tcnn::ivec2(uv * tcnn::vec2(resolution)), 0, resolution - 1)) + 0.5f) / tcnn::vec2(resolution); } return uv;}It generates a random UV coordinate inside a training image. UV is normalized to [0,1] × [0,1]. This UV is later turned into a ray shooting into the NeRF scene.
2.5.3 The Key Takeaway
NeRF Synthetic training uses the else branch almost always.
Meaning:
- UV is uniformly random
- PDF defaults to
1.0 - CDF importance sampling is disabled by default
2.6 Get Pixel Index
size_t pix_idx = pixel_idx(uv, resolution, 0);2.6.1 CUDA Function pixel_idx
inline NGP_HOST_DEVICE ivec2 image_pos(const vec2& pos, const ivec2& resolution){ return clamp(ivec2(pos * vec2(resolution)), 0, resolution - 1);}
inline NGP_HOST_DEVICE uint64_t pixel_idx(const ivec2& px, const ivec2& resolution, uint32_t img){ return px.x + px.y * resolution.x + img * (uint64_t)resolution.x * resolution.y;}
inline NGP_HOST_DEVICE uint64_t pixel_idx(const vec2& uv, const ivec2& resolution, uint32_t img){ return pixel_idx(image_pos(uv, resolution), resolution, img);}2.6.2 Base Version
inline __device__ uint64_t pixel_idx(const tcnn::vec2& uv, const tcnn::ivec2& resolution, uint32_t img) { tcnn::ivec2 px = tcnn::clamp(tcnn::ivec2(uv * tcnn::vec2(resolution)), 0, resolution - 1); return px.x + px.y * resolution.x + img * (uint64_t) resolution.x * resolution.y;}They map
uv (float normalized coordinates)→pixel(x,y)→ flat pixel index in entire dataset
CUDA Function image_pos()
inline NGP_HOST_DEVICE ivec2 image_pos(const vec2& pos, const ivec2& resolution){ return clamp(ivec2(pos * vec2(resolution)), 0, resolution - 1);}Input
pos = uv ∈ [0,1](normalized image space)resolution = (W,H)
What it does
-
pos * resolutionconverts normalized UV → pixel space Example → (0.2,0.5) * (800,800) → (160,400) -
Convert to integer
ivec2(...)(drop decimals) -
clamp(..., 0, resolution-1)ensures pixel cannot go outside image
Output
A valid pixel coordinate (x,y) inside the image:
0 ≤ x < width0 ≤ y < heightCUDA Function pixel_idx(px)
inline NGP_HOST_DEVICE uint64_t pixel_idx(const ivec2& px, const ivec2& resolution, uint32_t img){ return px.x + px.y * resolution.x + img * (uint64_t)resolution.x * resolution.y;}Meaning
This converts pixel index (x,y) + image number (img) into a 1D index for flattened dataset storage.
Breakdown:
So total index = index inside image + offset to image block
CUDA Function pixel_idx(uv) — UV version
inline NGP_HOST_DEVICE uint64_t pixel_idx(const vec2& uv, const ivec2& resolution, uint32_t img){ return pixel_idx(image_pos(uv, resolution), resolution, img);}This is just a convenience overload:
Steps internally:
uv → pixel(x,y) using image_pos()(x,y,img) → 1D index using pixel_idx()So this lets you write:
pixel_idx(uv, resolution, img);instead of:
ivec2 px = image_pos(uv, resolution);pixel_idx(px, resolution, img);2.7 Check Pixel Validity
if (read_rgba(uv, resolution, metadata[img].pixels, metadata[img].image_data_type).x < 0.0f){ return;}Given a pixel coordinate (either
uvor integerpx), look into GPU image data and return avec4(R,G,B,A)in linear RGB space.
2.7.1 CUDA Function read_rgba
inline NGP_HOST_DEVICE vec4 read_rgba(ivec2 px, const ivec2& resolution, const void* pixels, EImageDataType image_data_type, uint32_t img = 0){ switch (image_data_type) { default: // This should never happen. Bright red to indicate this. return vec4{5.0f, 0.0f, 0.0f, 1.0f}; case EImageDataType::Byte: { uint32_t val = ((uint32_t*)pixels)[pixel_idx(px, resolution, img)]; if (val == 0x00FF00FF) { return vec4(-1.0f); }
vec4 result = rgba32_to_rgba(val); result.rgb() = srgb_to_linear(result.rgb()) * result.a; return result; } case EImageDataType::Half: { __half val[4]; *(uint64_t*)&val[0] = ((uint64_t*)pixels)[pixel_idx(px, resolution, img)]; return vec4{(float)val[0], (float)val[1], (float)val[2], (float)val[3]}; } case EImageDataType::Float: return ((vec4*)pixels)[pixel_idx(px, resolution, img)]; }}inline NGP_HOST_DEVICE vec4 read_rgba(vec2 pos, const ivec2& resolution, const void* pixels, EImageDataType image_data_type, uint32_t img = 0){ return read_rgba(image_pos(pos, resolution), resolution, pixels, image_data_type, img);}It supports three image formats:
| Format | Stored As | Per Channel | Explanation |
|---|---|---|---|
Byte | uint32_t | 8-bit RGBA | sRGB → linear conversion with premultiply |
Half | __half[4] → packed in uint64_t | 16-bit float | No conversion, read directly |
Float | vec4* | 32-bit float | Pure float, no transformation |
Case 1: Byte — 8-bit texture stored as uint32_t
uint32_t val = ((uint32_t*)pixels)[pixel_idx(px, resolution, img)];if (val == 0x00FF00FF) { return vec4(-1.0f);}vec4 result = rgba32_to_rgba(val);result.rgb() = srgb_to_linear(result.rgb()) * result.a;return result;Explanation:
- Load 4 × 8-bit channels in one
uint32_t - If value is
0x00FF00FF, treat pixel as masked → returnsvec4(-1)meaning invalid pixel - Convert BGRA/ARGB → linear RGBA (
rgba32_to_rgba) - Convert sRGB → linear + premultiply by alpha
This format comes from NeRF synthetic datasets.
Case 2: Half — 16-bit floating point (stored compact)
__half val[4];*(uint64_t*)&val[0] = ((uint64_t*)pixels)[pixel_idx(...)]return vec4{(float)val[0], ... }Breakdown:
| Stored as | Read as | Why? |
|---|---|---|
| 4×half (each 16-bit) = 8 bytes | uint64_t load | faster & coalesced |
Then reinterpret as __half[4] | convert to float | for computation |
Used for lighter GPU memory footprint with HDR capability.
Case 3: Float — direct vec4
return ((vec4*)pixels)[pixel_idx(px, resolution, img)];Fastest — no conversion. Used when training directly with float images.
Second overload — UV input
inline vec4 read_rgba(vec2 pos, ...){ return read_rgba(image_pos(pos, resolution), ...);}Meaning:
- Convert → pixel coordinate
image_pos()=uv * resolution → clamp to image bounds - Call integer version
2.7.2 Base Version
inline __device__ float srgb_to_linear(float x) { return (x <= 0.04045f) ? (x * (1.f / 12.92f)) : powf((x + 0.055f) * (1.f / 1.055f), 2.4f);}
inline __device__ tcnn::vec4 read_rgba( const tcnn::vec2& uv, const tcnn::ivec2& resolution, const void* pixels, const uint32_t img = 0 // optional, default works same as before ) { // --------------------------------------------- // 1. Get pixel address from uv + resolution // --------------------------------------------- const uint64_t idx = pixel_idx(uv, resolution, img); const uint32_t rgba = static_cast<const uint32_t*>(pixels)[idx]; // packed 0xAARRGGBB
// --------------------------------------------- // 2. Masked pixel → skip (-1 = INVALID) // --------------------------------------------- if (rgba == 0x00FF00FFu) return {-1.f, -1.f, -1.f, -1.f};
// --------------------------------------------- // 3. Extract channels [0–255] → float [0–1] // --------------------------------------------- const float r = static_cast<float>((rgba >> 0) & 0xFF) * (1.f / 255.f); const float g = static_cast<float>((rgba >> 8) & 0xFF) * (1.f / 255.f); const float b = static_cast<float>((rgba >> 16) & 0xFF) * (1.f / 255.f); const float a = static_cast<float>((rgba >> 24) & 0xFF) * (1.f / 255.f);
return {srgb_to_linear(r) * a, srgb_to_linear(g) * a, srgb_to_linear(b) * a, a};}2.8 Determine Maximum Mip Level for Training
float max_level = max_level_rand_training ? (random_val(rng) * 2.0f) : 1.0f; // Multiply by 2 to ensure 50% of training is at max levelIt seems that NeRF Synthetic training always uses
max_level = 1.0fbecausemax_level_rand_trainingisfalseby default.
2.8.1 Base Version
float max_level = 1.0f; // defaultAs mentioned, NeRF Synthetic training does not use random mip levels. It’s safe to assume max_level = 1.0f always.
2.9 Get Transform with Rolling Shutter and Motion Blur
float motionblur_time = random_val(rng);...const mat4x3 xform = get_xform_given_rolling_shutter(training_xforms[img], metadata[img].rolling_shutter, uv, motionblur_time);Samples a random time in
[0,1]for motion blur simulation during training, then computes the camera-to-world transform at that time, accounting for rolling shutter effects.
2.9.1 Why Motion Blur?
In Instant-NGP, motionblur_time controls sampling along temporal exposure of rolling-shutter or moving scene. Think of it like simulating a camera where the shutter isn’t instantaneous—different rays observe the world at slightly different times during the frame capture.
2.10 CUDA Function get_xform_given_rolling_shutter
Ray ray_unnormalized; const Ray* rays_in_unnormalized = metadata[img].rays; if (rays_in_unnormalized) { // Rays have been explicitly supplied. Read them. ray_unnormalized = rays_in_unnormalized[pix_idx];
/* DEBUG - compare the stored rays to the computed ones const mat4x3 xform = get_xform_given_rolling_shutter(training_xforms[img], metadata[img].rolling_shutter, uv, 0.f); Ray ray2; ray2.o = xform[3]; ray2.d = f_theta_distortion(uv, principal_point, lens); ray2.d = (xform.block<3, 3>(0, 0) * ray2.d).normalized(); if (i==1000) { printf("\n%d uv %0.3f,%0.3f pixel %0.2f,%0.2f transform from [%0.5f %0.5f %0.5f] to [%0.5f %0.5f %0.5f]\n" " origin [%0.5f %0.5f %0.5f] vs [%0.5f %0.5f %0.5f]\n" " direction [%0.5f %0.5f %0.5f] vs [%0.5f %0.5f %0.5f]\n" , img,uv.x, uv.y, uv.x*resolution.x, uv.y*resolution.y, training_xforms[img].start[3].x,training_xforms[img].start[3].y,training_xforms[img].start[3].z, training_xforms[img].end[3].x,training_xforms[img].end[3].y,training_xforms[img].end[3].z, ray_unnormalized.o.x,ray_unnormalized.o.y,ray_unnormalized.o.z, ray2.o.x,ray2.o.y,ray2.o.z, ray_unnormalized.d.x,ray_unnormalized.d.y,ray_unnormalized.d.z, ray2.d.x,ray2.d.y,ray2.d.z); } */ } else { ray_unnormalized = uv_to_ray(0, uv, resolution, focal_length, xform, principal_point, vec3(0.0f), 0.0f, 1.0f, 0.0f, {}, {}, lens, distortion); if (!ray_unnormalized.is_valid()) { ray_unnormalized = {xform[3], xform[2]}; } }Some information may be outdated